주식투자 강화학습 절차(process)
2020-03-26 • rltrader • stock, 주식투자, reinforcement learning, rl, 강화학습, process, 절차 • 2 min read
강화학습은 환경, 에이전트, 신경망이 서로 상호작용하면서 학습을 수행하기 때문에 그 과정이 일반적인 머신러닝보다 복잡합니다. 여기서는 주식투자를 위한 강화학습 절차를 순서도와 함께 살펴봅니다.
주식투자 강화학습 순서도
강화학습으로 주식투자를 하는 방법은 다른 여느 강화학습 문제와 다르지 않습니다. 강화학습 프로세스는 다음과 같습니다.
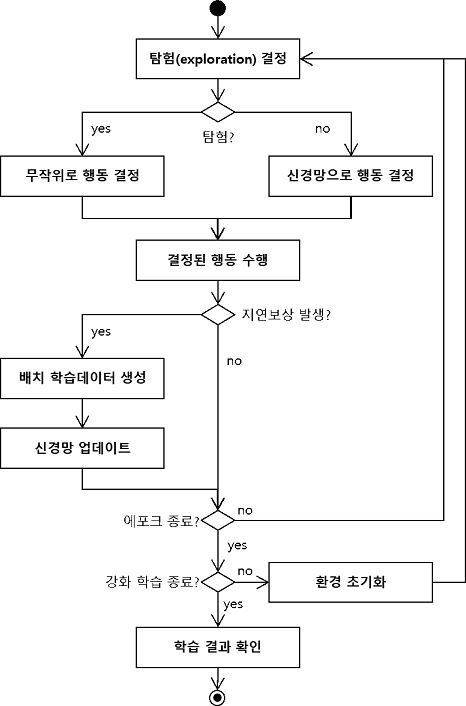
강화학습 프로세스
강화학습은 경험을 학습하는 것입니다. 경험을 충분히 쌓기 위해서 많이 반복합니다. 학습 대상 데이터 전부를 대상으로 한 차례 반복하는 과정을 에포크(epoch) 라고 합니다. 100번째 반복이라면 100에포크라고 부르면 됩니다.
행동 결정
한 에포크에서 경험을 얻기 위해 무작위로 행동을 해봐야 하는데, 이를 탐험(exploration)이라고 합니다. 일반적으로 강화학습 초반에는 탐험을 많이 하고 후반으로 갈수록 탐험을 적게 합니다.
탐험 비율을 엡실론(epsilon)이라고 합니다. 100번 반복한다고 했을 때 1에포크에서는 엡실론을 50%로 정하고, 점점 엡실론을 줄여서 100번째 에포크에서는 0%가 되게 하면 에포크가 커질수록 무작위로 하는 행동이 줄어듭니다. 경험이 쌓일수록 무작위로 하는 행동을 줄이는 것입니다.
무작위로 행동을 하지 않을 때는 신경망으로 행동을 결정합니다. 신경망의 출력값이 높은 행동을 선택합니다.
결정된 행동 수행
무작위로 결정한 행동이든 신경망으로 결정한 행동이든 에이전트는 결정된 행동을 수행합니다.
매수의 경우 에이전트는 주식을 사들일 현금이 있는지 확인하고, 매수가 가능할 경우 매수를 수행하고 그렇지 않으면 관망합니다. 매수했을 경우 매수금만큼 현금을 줄이고 매수한 주식 수만큼 보유 주식 수를 늘려줍니다.
매도의 경우 에이전트는 보유한 주식이 있는지 확인하고 보유한 주식이 있을 경우 매도를 수행하고 그렇지 않으면 관망합니다. 매도했을 경우 매도한 주식 수만큼 보유 주식 수에서 빼주고 매도금만큼 현금 보유액에 더해줍니다.
배치 학습 데이터 생성 및 신경망 업데이트
이렇게 주식투자를 하면서 지연 보상을 줄 수 있을지 판단합니다. 예를 들어 5% 이상의 이익 또는 손실을 지연 보상 기준으로 정해 보겠습니다. 즉, 투자를 하다가 5% 이상의 이익이나 5% 이상의 손실이 발생하면 그때까지의 상황과 행동을 학습 데이터로 생성합니다. 이 학습 데이터를 한꺼번에 적용해 신경망을 업데이트합니다. 이런 학습 방법을 배치(batch) 학습이라고 부릅니다.
학습을 진행하고 나면 신경망의 가중치들이 업데이트되어 이후에 진행되는 투자부터 바로 업데이트된 신경망의 결과가 반영됩니다.
지연 보상 기준을 낮게 잡으면 작은 배치 학습 데이터로 자주 학습을 수행할 가능성이 높으며 지연 보상 기준이 높으면 큰 배치 학습 데이터로 드물게 학습을 진행할 가능성이 높습니다.
