RLTrader의 데이터 관리 모듈 개발
2020-04-11 • rltrader • stock, 주식투자, reinforcement learning, rl, 강화학습, data manager, 데이터 관리 • 5 min read
데이터 관리 모듈은 차트 데이터와 학습 데이터를 생성하는 모듈로 자질 벡터를 정의하고 데이터를 전처리합니다.
코드 조각 1: 자질 벡터 정의
차트 데이터는 날짜, 시가, 고가, 저가, 종가, 거래량으로 구성됩니다. 학습 데이터의 경우 두 가지 버전으로 자질 벡터를 구성합니다.
import pandas as pd
import numpy as np
COLUMNS_CHART_DATA = ['date', 'open', 'high', 'low', 'close', 'volume']
COLUMNS_TRAINING_DATA_V1 = [
'open_lastclose_ratio', 'high_close_ratio', 'low_close_ratio',
'close_lastclose_ratio', 'volume_lastvolume_ratio',
'close_ma5_ratio', 'volume_ma5_ratio',
'close_ma10_ratio', 'volume_ma10_ratio',
'close_ma20_ratio', 'volume_ma20_ratio',
'close_ma60_ratio', 'volume_ma60_ratio',
'close_ma120_ratio', 'volume_ma120_ratio',
]
COLUMNS_TRAINING_DATA_V2 = [
'per', 'pbr', 'roe',
'open_lastclose_ratio', 'high_close_ratio', 'low_close_ratio',
'close_lastclose_ratio', 'volume_lastvolume_ratio',
'close_ma5_ratio', 'volume_ma5_ratio',
'close_ma10_ratio', 'volume_ma10_ratio',
'close_ma20_ratio', 'volume_ma20_ratio',
'close_ma60_ratio', 'volume_ma60_ratio',
'close_ma120_ratio', 'volume_ma120_ratio',
'market_kospi_ma5_ratio', 'market_kospi_ma20_ratio',
'market_kospi_ma60_ratio', 'market_kospi_ma120_ratio',
'bond_k3y_ma5_ratio', 'bond_k3y_ma20_ratio',
'bond_k3y_ma60_ratio', 'bond_k3y_ma120_ratio'
]
COLUMNS_TRAINING_DATA_V1의 경우 차트 데이터에서 전처리로 얻을 수 있는 자질로만 구성돼 있고 COLUMNS_TRAINING_DATA_V2는 차트 데이터 외에 기본적 분석 지표인 PER, PBR, ROE와 코스피 지수, 국채 3년 데이터를 추가로 가집니다.
코드 조각 2: 데이터 전처리 함수
다음은 차트 데이터를 전처리해 학습 데이터에서 사용하는 자질을 생성하는 함수를 보여줍니다.
def preprocess(data):
windows = [5, 10, 20, 60, 120]
for window in windows:
data['close_ma{}'.format(window)] = \
data['close'].rolling(window).mean()
data['volume_ma{}'.format(window)] = \
data['volume'].rolling(window).mean()
data['close_ma%d_ratio' % window] = \
(data['close'] - data['close_ma%d' % window]) \
/ data['close_ma%d' % window]
data['volume_ma%d_ratio' % window] = \
(data['volume'] - data['volume_ma%d' % window]) \
/ data['volume_ma%d' % window]
data['open_lastclose_ratio'] = np.zeros(len(data))
data.loc[1:, 'open_lastclose_ratio'] = \
(data['open'][1:].values - data['close'][:-1].values) \
/ data['close'][:-1].values
data['high_close_ratio'] = \
(data['high'].values - data['close'].values) \
/ data['close'].values
data['low_close_ratio'] = \
(data['low'].values - data['close'].values) \
/ data['close'].values
data['close_lastclose_ratio'] = np.zeros(len(data))
data.loc[1:, 'close_lastclose_ratio'] = \
(data['close'][1:].values - data['close'][:-1].values) \
/ data['close'][:-1].values
data['volume_lastvolume_ratio'] = np.zeros(len(data))
data.loc[1:, 'volume_lastvolume_ratio'] = \
(data['volume'][1:].values - data['volume'][:-1].values) \
/ data['volume'][:-1] \
.replace(to_replace=0, method='ffill') \
.replace(to_replace=0, method='bfill').values
return data
차트 데이터는 preprocess() 함수의 인자로 들어오며 DataFrame 객체입니다. 이를 출력해 보면 다음 그림과 같습니다.
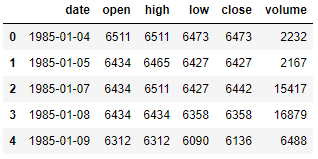
…
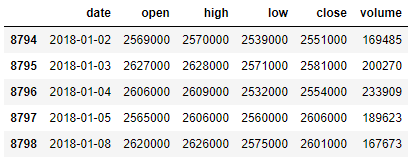
차트 데이터 예제의 head와 tail
과거의 주가와 현재의 주가가 크게 차이가 나기 때문에 이 값을 그대로 학습에 사용하기는 어렵습니다. 그러므로 현재 종가와 전일 종가의 비율, 이동평균 종가의 비율, 현재 거래량과 전일 거래량의 비율, 이동평균 거래량의 비율을 학습에 사용합니다.
구하려고 하는 이동평균 윈도우는 5, 10, 20, 60, 120입니다. 각 이동평균 크기에 대해 close_ma{이동평균크기}와 volume_ma{윈도우} 데이터를 만들어 냅니다.
파이썬 팁: Pandas의 rolling(window) 함수는 window 크기만큼 데이터를 묶어서 합, 평균, 표준편차 등을 계산할 수 있게 준비합니다. 이를 이동합, 이동평균, 이동표준편차라고 합니다
- 이동합(moving sum):
<Pandas 객체>.rolling().sum()- 이동평균(moving average):
<Pandas 객체>.rolling().mean()- 이동표준편차(moving standard deviation):
<Pandas 객체>.rolling().std()이동합은 롤링합(rolling sum), 이동평균은 롤링평균(rolling mean, rolling average), 이동표준편차는 롤링표준편차(rolling standard deviation)라고도 합니다.
이어서 이동평균 종가 비율과 이동평균 거래량 비율을 구합니다.
다음은 차트 데이터를 전처리한 후에 추가되는 열을 보여줍니다. 종가와 거래량과는 다르게 이동평균 값은 float 값으로 소수점을 가질 수 있습니다.
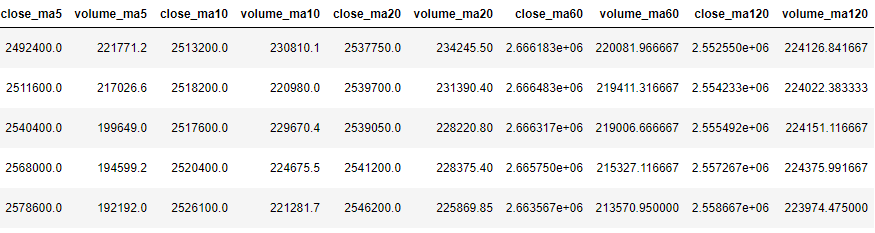
차트 데이터 전처리 과정에서 추가되는 열 (1)
각 이동평균 윈도우에 대해 이동평균 종가 비율, 이동평균 거래량 비율을 구합니다. 즉, close_ma5_ratio, close_ma10_ratio, close_ma20_ratio, close_ma60_ratio, close_ma120_ratio, volume_ma5_ratio, volume_ma10_ratio, volume_ma20_ratio, volume_ma60_ratio, volume_ma120_ratio를 구합니다.
이동평균 종가 비율을 구하는 방법은 현재 종가에 이동평균 값을 빼고 그 값에 이동평균 값을 나누는 것입니다. 이동평균 거래량 비율 역시 같은 방식으로 계산합니다.
다음은 위에서 구한 학습 데이터 특징의 예를 보여줍니다.
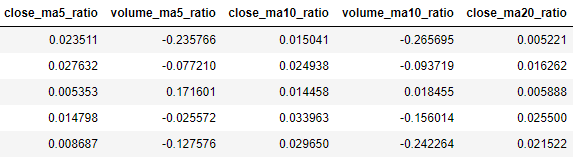
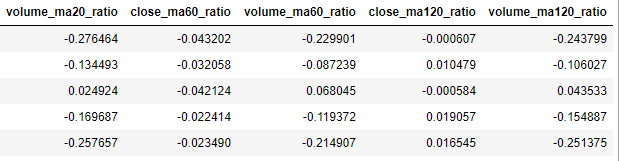
차트 데이터 전처리 과정에서 추가되는 열 (2)
이어서 시가/전일종가 비율(open_lastclose_ratio)을 구합니다. 첫 번째 행은 전일 값이 없거나 그 값이 있더라도 알 수 없기 때문에 전일 대비 종가 비율을 구하지 못합니다. 그래서 두 번째 행부터 마지막 행까지 open_lastclose_ratio 열에 시가/전일종가 비율을 저장합니다. 시가/전일종가 비율을 구하는 방식은 현재 종가에서 전일 종가를 빼고 전일 종가로 나누는 것입니다.
비슷한 방식으로 고가/종가 비율(high_close_ratio), 저가/종가 비율(low_close_ratio), 종가/전일종가 비율(close_lastclose_ratio), 거래량/전일거래량 비율(volume_lastvolume_ratio)을 계산합니다. 다만 거래량/전일거래량 비율을 구할 때는 거래량 값이 0이면 이전의 0이 아닌 값으로 바꿔줍니다.
파이썬 팁: Pandas의 DataFrame 데이터에서 일부 데이터를 잘라서 가져올 수 있습니다. 이를 슬라이스(slice, 조각내기)라고 합니다. DataFrame은 행과 열로 구성되는데,
loc()함수로 행과 열을 각각 슬라이스할 수 있습니다.예를 들어 다음과 같은 DataFrame 객체를 data_frame이라고 할 때,
index a b c 0 1 2 3 1 4 5 6 2 7 8 9 b번 열에서 1, 2행을 가져오고 싶다면 다음과 같이 loc() 함수를 쓸 수 있습니다.
data_frame.loc(1:, 'b')data_frame.loc([1, 2], 'b')두 경우 모두 결과는 다음처럼 같으나, 그 의미는 다릅니다.
index b 1 5 2 8
loc()함수의 첫 번째 인자에'1:'을 넣으면 두 번째 행부터 마지막 행까지 슬라이스하고,[1, 2]를 넣으면 두 번째와 세 번째 행을 슬라이스합니다.파이썬 팁: Pandas의
replace()함수로 특정 값을 바꿀 수 있습니다. 특정 값을 이전의 값으로 변경하고자 할 때는ffill메서드를 사용하고, 이후의 값으로 변경하고자 할 때는bfill메서드를 사용합니다. series가[1, 3, 0, 5, 7]일 때 결과는 다음과 같습니다.
series.replace(to_replace=0, method='ffill')결과:
[1, 3, 3, 5, 7]
series.replace(to_replace=0, method='bfill')결과:
[1, 3, 5, 5, 7]
다음은 이렇게 계산된 후의 학습 데이터 일부를 보여줍니다.
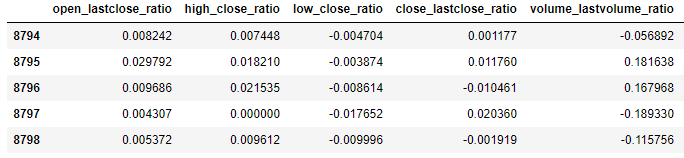
차트 데이터 전처리 과정에서 추가되는 열 (3)
코드 조각 3: 차트 데이터 및 학습 데이터 로드 함수
다음 코드조각은 강화학습 실행 모듈에서 호출하는 함수로 차트 데이터와 학습 데이터를 준비해 반환합니다.
데이터 관리 모듈: 차트 데이터 및 학습 데이터 로드 함수
def load_data(fpath, date_from, date_to, ver='v2'):
header = None if ver == 'v1' else 0
data = pd.read_csv(fpath, thousands=',', header=header,
converters={'date': lambda x: str(x)})
# 데이터 전처리
data = preprocess(data)
# 기간 필터링
data['date'] = data['date'].str.replace('-', '')
data = data[(data['date'] >= date_from) & (data['date'] <= date_to)]
data = data.dropna()
# 차트 데이터 분리
chart_data = data[COLUMNS_CHART_DATA]
# 학습 데이터 분리
training_data = None
if ver == 'v1':
training_data = data[COLUMNS_TRAINING_DATA_V1]
elif ver == 'v2':
data.loc[:, ['per', 'pbr', 'roe']] = \
data[['per', 'pbr', 'roe']].apply(lambda x: x / 100)
training_data = data[COLUMNS_TRAINING_DATA_V2]
training_data = training_data.apply(np.tanh)
else:
raise Exception('Invalid version.')
return chart_data, training_data
load_data() 함수는 CSV 파일 경로, 시작 날짜, 끝 날짜를 입력으로 받습니다.
먼저 CSV 파일을 파이썬 Pandas 라이브러리로 읽어옵니다. Pandas의 read_csv() 함수로 CSV 파일을 쉽게 읽어올 수 있습니다. 여기서 주의할 점은 CSV 파일명에 한글을 포함하지 않아야 한다는 점입니다.
Pandas의 read_csv() 함수의 첫 번째 인자에 이 파일 경로를 입력합니다. thousands 파라미터로 ','를 넣어주면 1,234,567과 같이 천 단위로 콤마(,)가 붙은 값을 숫자로 인식합니다. header 파라미터에 None을 넣어준 것은 저장한 CSV에 헤더가 없다는 것을 명시하기 위해서입니다. 만약 CSV 파일에 헤더 값을 넣어줬다면 이 파라미터는 넣지 않아도 됩니다.
파이썬 팁: Pandas의
read_csv()함수의 명세는 다음 웹사이트에서 확인할 수 있습니다.https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html
read파라미터로sep,header,engine,thousands,encoding등이 있습니다.파이썬 팁: CSV를 읽을 때 다음과 같은 인코딩 관련 에러가 발생하면 CSV 파일을 저장할 때 어떤 인코딩을 선택했는지 확인해야 합니다.
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc5 in position 0: invalid continuation byte위 에러는 CSV를 윈도우 기본인
CP949또는EUC-KR로 저장했는데UTF-8로 읽을 때 발생합니다. 이 경우 Pandasread_csv()함수 파라미터에encoding='CP949'를 추가해서read_csv(<파일명>, encoding='CP949')와 같이 호출하면 해결됩니다.CSV 파일에 한글이 없으면 인코딩 에러는 발생하지 않을 것입니다.
파이썬 팁: 파일명에 한글이 포함된 경우 Pandas의
read_csv()를 호출할 때 다음과 같은 에러가 발생할 수 있습니다.
File "pandas/_libs/parsers.pyx", line 394, in pandas._libs.parsers.TextReader.__cinit__ (pandas\_libs\parsers.c:4209)
File "pandas/_libs/parsers.pyx", line 712, in pandas._libs.parsers.TextReader._setup_parser_source (pandas\_libs\parsers.c:8895)
OSError: Initializing from file failed
이 경우 파일명을 영문과 숫자로만 구성하거나 read_csv() 함수에 engine='python'를 넣어서 read_csv(<파일명>, engine='python')과 같이 호출하면 됩니다. 꼭 파일명에 한글을 넣을 필요가 없다면 파일명을 영문과 숫자로만 구성할 것을 권장합니다.
그리고 데이터를 전처리하기 위해서 preprocess() 함수를 호출합니다. 전처리된 데이터에서 load_data() 함수의 인자로 들어온 시작 날짜와 끝 날짜에 해당하는 데이터만 남깁니다.
그리고 차트 데이터와 학습 데이터를 각가 분리해 반환합니다. 이때 학습 데이터의 자질은 ver 인자에 따라 달라집니다.
