딥러닝이란?
2020-03-10 • rltrader • deep learning, 딥러닝 • 4 min read
이번 장에서는 딥러닝(deep learning)과 강화학습(reinforcement learning)의 이론과 적용 사례를 소개합니다. 이 책은 강화학습을 주식투자에 적용하는 것과 파이썬으로 강화학습 기반 주식투자 시스템을 구현하는 것이 목적입니다. 여기서 딥러닝을 다루는 이유는 강화학습이 딥러닝의 일환으로 볼 수 있기 때문입니다. 그래서 딥러닝의 전반적인 이론을 먼저 소개하고 강화학습의 이론을 이어서 소개합니다.
딥러닝 개요
이번 절에서는 딥러닝이 무엇이고 딥러닝으로 할 수 있는 게 무엇이며 딥러닝이 최근에 와서야 주목받는 이유에 대해서 다룹니다.
딥러닝의 정의와 역사
딥러닝의 표준 정의는 없지만 일반적으로 딥러닝은 머신러닝(machine learning, ML)의 한 종류로 주로 인공 신경망(artificial neural network, ANN)의 발전된 모델로 볼 수 있습니다. 이 기법들은 인공지능(artifical intelligence, AI)을 실현하기 위한 도구로서 사용됩니다.
사실 딥러닝은 1950년대부터 연구되어 왔습니다. 즉 딥러닝은 새로운 개념이 아닌 오래된 역사를 가진 기술로 볼 수 있습니다. 시대별 주요 특징을 살펴보면 다음 그림과 같습니다.

1950년대에 등장한 퍼셉트론(perceptron)은 인공 신경망의 시초라고 할 수 있습니다. 이후 1960년대에 인공 신경망 연구가 활발히 진행되어 왔습니다. 그러나 1969년 ≪Perceptrons≫라는 책이 출간되었는데 이 책은 퍼셉트론의 치명적인 한계점을 밝히고 증명까지 담고 있었습니다. 이후 1970년대에는 많은 학자들로부터 인공 신경망이 외면받게 되는 암흑기에 들어섭니다.
1980년대에는 인공 신경망 연구가 다시 주목을 받기 시작합니다. 이는 1986년에 오차 역전파법(back propagation)을 적용하여 다층의 인공 신경망을 학습하는 방법이 고안된 덕택이라 볼 수 있습니다. 이 시대에 심층 신경망(deep neural network, DNN), 순환 신경망(recurrent neural network, RNN), 합성곱 신경망(convolutional neural network, CNN) 등이 발전되어 왔습니다.
1990년대에는 발전된 형태의 인공 신경망들이 등장했습니다. 고급 순환 신경망인 LSTM이 1997년에, 고급 합성곱 신경망인 LeNet-5가 1998년에 발표되었습니다.
2000년대에는 딥러닝(deep learning)이라는 이름으로 인공 신경망이 각광을 받기 시작합니다. 저명한 정보 기술 연구 및 조사 기관인 가트너(Gartner)가 딥러닝을 10대 전략 기술로 선정합니다.
2010년대에는 구글의 딥마인드(Deep Mind)가 익히 알려진 알파고를 공개합니다. 이 이후로 한국에서도 딥러닝이 폭발적인 주목을 받게 됩니다.
딥러닝이 최근에 주목받는 이유
왜 최근에 와서야 딥러닝이 주목을 받을 수 있었을까요? 여러 이유가 있겠지만 크게 두 가지 이유를 들어 보겠습니다.
우선 컴퓨터의 연 산 능력이 좋아졌습니다. 인공 신경망을 학습시키는 일은 많은 연산을 필요로 합니다. 복잡한 문제를 풀기 위해서는 인공 신경망의 구조를 매우 복잡하고 정교하게 만들어야 합니다. 이 경우 방대한 연산이 발생하게 되는데 GPU 사용, 분산처리 등으로 이러한 연산이 현실적으로 가능하게 되었습니다.
또 하나의 이유는 빅데이터(big data)의 등장입니다. 인공 신경망을 제대로 학습시키기 위해서는 방대한 양질의 데이터가 필요한데 빅데이터를 학습함으로써 인공 신경망의 정확도를 상당히 향상시킬 수 있었습니다.
딥러닝 이론들을 완벽하게 알지 못해도 목표로 삼은 강화학습을 이용한 주식투자 시스템을 개발하는 데 무리는 없습니다. 인공 신경망을 텐서플로(TensorFlow), 케라스(Keras) 등의 라이브러리를 사용하면 쉽게 구현할 수 있기 때문입니다. 이 책에서는 딥러닝 관련 이론들을 소개하는 데 그치고, 대신에 코드로 상세하게 구현해 보는 데 역점을 둡니다.
딥러닝으로 풀고자 하는 문제
딥러닝뿐만 아니라 여타 머신러닝에서 풀고자 하는 문제들은 일반적으로 분류 문제, 군집화 문제, 회귀 문제로 구분할 수 있습니다.
분류(classification)
데이터의 부류(class)를 알아내기 위한 문제입니다. 예로서 자동차의 길이, 너비, 높이, 바퀴 크기, 엔진 마력 등의 특징(feature)을 보고 경차, 준중형차, 중형차, 대형차 중 한 가지 부류로 분류하는 문제를 들 수 있습니다.
군집화(clustering)
데이터 인스턴스(data instance)[1]들을 그룹화하기 위한 문제입니다. 즉, 비슷한 특징을 가지는 데이터 인스턴스들끼리 그룹화하는 것입니다. 예를 들어 자동차의 길이, 너비, 높이, 바퀴 크기, 엔진 마력 등의 특징들을 보고 비슷한 인스턴스끼리 그룹화합니다. 그룹화된 결과를 보고 그룹 1은 경차, 그룹 2는 준준형차, 등으로 정해 주기 위해서는 사람의 개입이 필요합니다.
회귀(regression)
불완전한 데이터의 값(value)를 알아내기 위한 문제입니다. 예를 들어 한 데이터 인스턴스 중에 자동차의 너비, 높이, 바퀴의 크기, 엔진 마력 등의 특징을 아는데 길이를 모른다고 할 때, 다른 데이터 인스턴스들의 값을 근거로 불완전한 데이터로 구성된 인스턴스의 길이 특징을 예측할 수 있습니다.
각 문제들을 머신러닝(machine learning) 관점에서 풀 수 있는데, 학습 방법을 지도학습, 비지도학습, 강화학습으로 구분할 수 있습니다.
지도학습(supervised learning)
레이블(label)이 있는 데이터를 학습하는 방법으로 주로 분류와 회귀 문제를 다룹니다. 레이블이 있다는 것은 정답이 있다는 의미이기 때문에 비교적 학습이 쉽고 효과적입니다. 그러나 레이블을 데이터마다 부여하려면 일반적으로 많은 비용이 요구됩니다. 비용은 돈이 될수도, 시간이 될 수도, 많은 경우는 둘 다가 될 수 있습니다. 학습 데이터는 적게는 수백 개 많게는 수백만, 수천만, 혹은 그 이상으로 방대합니다. 이러한 데이터에 사람이 일일이 레이블을 부여하는 것은 때론 불가능할수도 있습니다.
다음 그림은 지도학습 학습데이터의 예로 그 유명한 Iris 데이터의 일부를 보여줍니다.
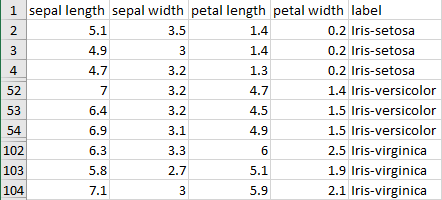
지도학습의 학습 데이터 샘플 (출처: https://archive.ics.uci.edu/ml/)
이 데이터는 네 개의 특징과 레이블로 구성됩니다. 각 데이터 인스턴스는 세 가지 레이블 “Iris-setosa”, “Iris-versicolor”, “Iris-virginica” 중에서 하나의 레이블을 부여받습니다.
비지도학습(unsupervised learning)
레이블이 없는 데이터를 학습하는 방법입니다. 주로 데이터를 그룹화하거나 데이터의 특징을 분석하기 위해서 사용합니다. 비지도학습은 정답이 없는 데이터를 분석하는 것이므로 데이터에 레이블을 부여할 필요가 없습니다. 즉 데이터를 준비하기 위해 비용이 적습니다. 그러나 분석된 결과인 군집들이 어떠한 의미를 가지는지는 사람이 개입하여 확인해야 하는 경우가 많습니다.
Iris 데이터에서 label을 제외하면 다음 그림과 같이 비지도학습으로 분석할 데이터가 됩니다. 이 데이터를 세 개의 그룹으로 (잘) 군집화하면 레이블은 모르지만 각 그룹이 “Iris-setosa”, “Iris-versicolor”, “Iris-virginica”을 의미하게 됩니다.
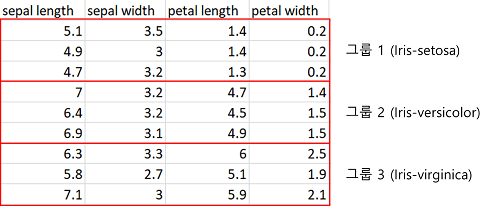
비지도학습의 학습 데이터 샘플 (출처: https://archive.ics.uci.edu/ml/)
강화학습(reinforcement learning)
에이전트가 어떠한 환경에서 행동을 수행했을 때 보상을 함으로써, 에이전트는 그 보상을 최대로 하는 행동을 수행하도록 학습하게 하는 방법입니다. 주로 어떠한 행동을 결정하는 분류 문제나 보상을 예측하는 회귀 문제를 다룹니다. 강화학습은 레이블이 없는 데이터를 학습할 수 있지만 에이전트와 환경을 구성하는 추가적인 비용을 필요로 합니다.
이 책의 범위인 주식투자 시뮬레이션에서 강화학습을 사용하므로 강화학습에 대해서는 3장과 4장에서 더 상세히 다룹니다.
