네이버 금융에서 주식 종목의 일별 주가 크롤링하기
2018-07-05 • quant • 크롤링, 네이버 금융, 일별 주가, crawling, naver finance • 2 min read
대규모 크롤링은 문제가 될 수 있으니 주의하시길 바랍니다.
네이버 금융에서 일별 주가는 이 페이지 (https://finance.naver.com/item/sise_day.nhn?code=035420)가 <iframe>으로 부착되어 있습니다.
우리는 이 페이지를 크롤링하여 주식 종목의 일별 주가를 간편하게 가져올 수 있습니다.
여기서 사용하는 파이썬 라이브러리는 다음과 같습니다 - requests: HTTP 라이브러리 - Beautiful Soup: HTML, XML 파싱 라이브러리 - pandas: 자료구조 라이브러리 - tqdm: Progress 확인 라이브러리
먼저 크롤링할 종목의 종목코드를 확인합니다. 여기서는 NAVER(035420) 종목의 일별 주가를 크롤링 해보겠습니다.
code = '035420' # NAVER
code
'035420'
이제 크롤링할 대상의 URL을 준비하고 requests 라이브러리를 사용하여 호출합니다.
import requests
url = 'http://finance.naver.com/item/sise_day.nhn?code={code}'.format(code=code)
res = requests.get(url)
res.encoding = 'utf-8'
res.status_code
200
아래 URL을 방문해 보면 "일별 시세" 테이블만 가져오게 됩니다.
url
'http://finance.naver.com/item/sise_day.nhn?code=035420'
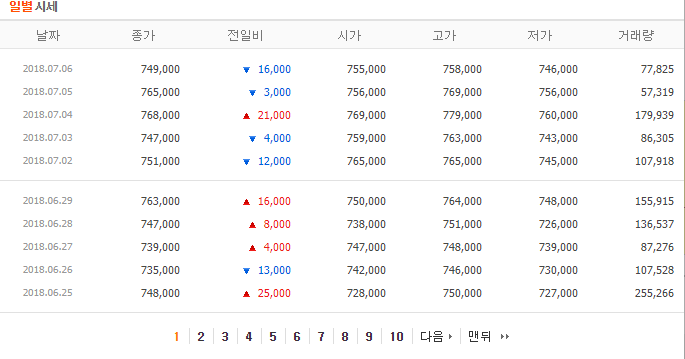
대부분의 웹브라우저에 있는 "소스보기" 기능을 이용하여 이 페이지의 전체 HTML 코드를 확인해 보시기 바랍니다.
수신한 데이터로 BeautifulSoup의 인스턴스를 생성합니다. 이 때, 생성자의 두번째 인자로 'lxml'을 입력해 줍니다.
from bs4 import BeautifulSoup
soap = BeautifulSoup(res.text, 'lxml')
먼저 Pagination 영역을 가져와서 마지막 페이지 번호를 알아냅니다. 테이블 아래 부분에 Pagination 영역이 있는데, 이 또한 <table>로 구성되어 있습니다.
el_table_navi = soap.find("table", class_="Nnavi")
el_td_last = el_table_navi.find("td", class_="pgRR")
pg_last = el_td_last.a.get('href').rsplit('&')[1]
pg_last = pg_last.split('=')[1]
pg_last = int(pg_last)
pg_last
389
마지막 페이지 번호 내에서 원하는 페이지의 테이블을 읽어올 수 있습니다. parse_page() 함수는 종목과 페이지 번호를 입력으로 받아서 일별 주가를 Pandas DataFrame 객체로 반환합니다.
import traceback
import pandas as pd
def parse_page(code, page):
try:
url = 'http://finance.naver.com/item/sise_day.nhn?code={code}&page={page}'.format(code=code, page=page)
res = requests.get(url)
_soap = BeautifulSoup(res.text, 'lxml')
_df = pd.read_html(str(_soap.find("table")), header=0)[0]
_df = _df.dropna()
return _df
except Exception as e:
traceback.print_exc()
return None
parse_page(code, 1)
| 날짜 | 종가 | 전일비 | 시가 | 고가 | 저가 | 거래량 | |
|---|---|---|---|---|---|---|---|
| 1 | 2018.07.06 | 749000.0 | 16000.0 | 755000.0 | 758000.0 | 746000.0 | 77825.0 |
| 2 | 2018.07.05 | 765000.0 | 3000.0 | 756000.0 | 769000.0 | 756000.0 | 57319.0 |
| 3 | 2018.07.04 | 768000.0 | 21000.0 | 769000.0 | 779000.0 | 760000.0 | 179939.0 |
| 4 | 2018.07.03 | 747000.0 | 4000.0 | 759000.0 | 763000.0 | 743000.0 | 86305.0 |
| 5 | 2018.07.02 | 751000.0 | 12000.0 | 765000.0 | 765000.0 | 745000.0 | 107918.0 |
| 9 | 2018.06.29 | 763000.0 | 16000.0 | 750000.0 | 764000.0 | 748000.0 | 155915.0 |
| 10 | 2018.06.28 | 747000.0 | 8000.0 | 738000.0 | 751000.0 | 726000.0 | 136537.0 |
| 11 | 2018.06.27 | 739000.0 | 4000.0 | 747000.0 | 748000.0 | 739000.0 | 87276.0 |
| 12 | 2018.06.26 | 735000.0 | 13000.0 | 742000.0 | 746000.0 | 730000.0 | 107528.0 |
| 13 | 2018.06.25 | 748000.0 | 25000.0 | 728000.0 | 750000.0 | 727000.0 | 255266.0 |
뒷 페이지로 갈수록 과거의 일별 주가를 가져올 수 있습니다. 이 데이터를 모두 가져올 필요는 없을 것이므로 여기서는 기준 일자 이후만 가져올 수 있도록 로직을 구현합니다.
import datetime
str_datefrom = datetime.datetime.strftime(datetime.datetime(year=2018, month=1, day=1), '%Y.%m.%d')
str_datefrom
'2018.01.01'
str_dateto = datetime.datetime.strftime(datetime.datetime.today(), '%Y.%m.%d')
str_dateto
'2018.07.08'
df = None
for page in range(1, pg_last+1):
_df = parse_page(code, page)
_df_filtered = _df[_df['날짜'] > str_datefrom]
if df is None:
df = _df_filtered
else:
df = pd.concat([df, _df_filtered])
if len(_df) > len(_df_filtered):
break
df.tail()
| 날짜 | 종가 | 전일비 | 시가 | 고가 | 저가 | 거래량 | |
|---|---|---|---|---|---|---|---|
| 2 | 2018.01.08 | 950000.0 | 42000.0 | 915000.0 | 953000.0 | 908000.0 | 196338.0 |
| 3 | 2018.01.05 | 908000.0 | 15000.0 | 893000.0 | 918000.0 | 880000.0 | 136811.0 |
| 4 | 2018.01.04 | 893000.0 | 22000.0 | 879000.0 | 897000.0 | 873000.0 | 130112.0 |
| 5 | 2018.01.03 | 871000.0 | 14000.0 | 876000.0 | 884000.0 | 864000.0 | 84790.0 |
| 9 | 2018.01.02 | 885000.0 | 15000.0 | 871000.0 | 885000.0 | 870000.0 | 93587.0 |
이제 완성된 일별 주가 DataFrame 객체를 CSV 파일로 저장합니다. 먼저 저장할 경로를 준비합니다.
import os
path_dir = 'data/2018-07-05-crawling'
if not os.path.exists(path_dir):
os.makedirs(path_dir)
path = os.path.join(path_dir, '{code}_{date_from}_{date_to}.csv'.format(code=code, date_from=str_datefrom, date_to=str_dateto))
path
'data/2018-07-05-crawling/035420_2018.01.01_2018.07.08.csv'
그리고 Pandas DataFrame 함수인 to_csv()를 호출하여 CSV 파일을 생성합니다.
df.to_csv(path, index=False)
