파이썬으로 BM25와 BM25F 구현하기
이 포스트에서는 정보 검색 (Information Retrieval) 분야에서 빼 놓을 수 없는 BM25, BM25Simple, BM25F를 파이썬으로 구현해 봅니다. 검색 엔진을 구현해보고자 하는 것이 아니라 BM25, BM25FSimple, BM25F에 대해 코드레벨에서 이해해 보고자 하는 것입니다. 이론은 Okapi BM25에서 확인하세요.
먼저 문서를 준비합니다. 여기서는 몇몇 뉴스기사를 직접 긁어왔습니다. 글이 너무 길어지기 때문에 별도의 파일로 참조합니다.
BM25F의 경우 섹션을 나눠줘야 하는데, 여기서는 간단하게 title, body로 두 개의 섹션을 고려합니다. 다음 코드는 정규식으로 특수문자를 제거하고 BM25를 위한 문서와 BM25F를 적용하기 위한 문서 데이터를 준비합니다.
import re
docs_bm25 = [re.sub('([^a-zA-Z0-9ㄱ-ㅣ가-힣\s])+',' ', doc).split() for doc in docs_bm25_raw]
docs_bm25f = [re.sub('([^a-zA-Z0-9ㄱ-ㅣ가-힣\s])+',' ', doc).split('\n') for doc in docs_bm25_raw]
docs_bm25f = [[title.split(), body.split()] for title, body in docs_bm25f]
다음 코드는 BM25 클래스 입니다.
from functools import reduce
from collections import defaultdict
import numpy as np
import pandas as pd
class BM25:
def __init__(self, docs):
self.docs = docs # array of term vectors
self.N = 10000 # len(self.docs)
self.avdl = reduce(lambda dl1, dl2: dl1 + dl2, map(lambda d: len(d), self.docs)) / len(self.docs)
def rank(self, q, b=0.5, k=2):
# initialize
B_d = [] # B constant for docs
tf_q = [[] for _ in range(len(q))] # term frequency vector of docs for query terms
n_q = [0] * len(q) # doc frequency vectors for query terms
for idx_d, d in enumerate(self.docs):
# provision
d = np.array(d)
# document length and B
dl = len(d)
B_d.append((1-b) / (b * (dl / self.avdl)))
# term frequency
for idx_q, queryterm in enumerate(q):
d_query_included = np.core.defchararray.find(d, queryterm)
tf_queryterm = len(d_query_included[d_query_included != -1])
tf_q[idx_q].append(tf_queryterm)
# updating n
if tf_queryterm > 0:
n_q[idx_q] += 1
# tf normalization
tf_q = np.array(tf_q)
B_d = np.array(B_d)
tf_q_norm = tf_q / B_d.reshape((1,len(B_d))).repeat(len(q), axis=0)
# inverse document frequency
n_q = np.array(n_q)
idf_q = np.log((self.N - n_q + .5) / (n_q + .5))
# weight
w_q = (tf_q_norm / (k + tf_q_norm)) * idf_q.reshape((len(q), 1)).repeat(len(self.docs), axis=1)
w = w_q.sum(axis=0)
docidx_ranked = w.argsort(axis=0)
# result as data frame
df_result = pd.DataFrame(columns=['docid', 'w', 'doc'], data={
'docid': list(range(1, len(self.docs)+1)),
'w': w,
'doc': self.docs
})
return df_result.sort_values(by='w')[::-1].reset_index(drop=True)
다음은 BM25FSimple 클래스 코드 입니다.
from functools import reduce
from collections import defaultdict
import numpy as np
import pandas as pd
class BM25FSimple:
def __init__(self, docs, v):
self.docs = docs # array of field term vectors
self.v = v # stream weight
self.N = 10000 # len(self.docs)
# calculate avdl after flattening self.docs
self.avdl = reduce(lambda dl1, dl2: dl1 + dl2, map(lambda d: len(d), np.array(self.docs).flatten())) / len(self.docs)
def rank(self, q, b=0.5, k=2):
# initialize
B_d = [] # B constant for docs
tf_q = [[] for _ in range(len(q))] # term frequency vector of docs for query terms
n_q = [0] * len(q) # doc frequency vectors for query terms
for idx_d, d in enumerate(self.docs):
dl = 0
tf_queryterm = 0
for stream, stream_weight in zip(d, self.v):
# provision
stream = np.array(stream)
# document length
dl += len(stream) * stream_weight
# term frequency
for idx_q, queryterm in enumerate(q):
tf_queryterm = 0
for stream, stream_weight in zip(d, self.v):
stream_query_included = np.core.defchararray.find(stream, queryterm)
tf_queryterm += len(stream_query_included[stream_query_included != -1]) * stream_weight
tf_q[idx_q].append(tf_queryterm)
# updating n
if tf_queryterm > 0:
n_q[idx_q] += 1
# B; sum of length of streams
B_d.append((1-b) / (b * (dl / self.avdl)))
# tf normalization
tf_q = np.array(tf_q)
B_d = np.array(B_d)
tf_q_norm = tf_q / B_d.reshape((1,len(B_d)))
# inverse document frequency
n_q = np.array(n_q)
idf_q = np.log((self.N - n_q + .5) / (n_q + .5))
# weight
w_q = (tf_q_norm / (k + tf_q_norm)) * idf_q.reshape((len(q), 1))
w = w_q.sum(axis=0)
docidx_ranked = w.argsort(axis=0)
# result as data frame
df_result = pd.DataFrame(columns=['docid', 'w', 'doc'], data={
'docid': list(range(1, len(self.docs)+1)),
'w': w,
'doc': self.docs
})
return df_result.sort_values(by='w')[::-1].reset_index(drop=True)
다음 코드는 BM25F 클래스 코드 입니다.
from functools import reduce
from collections import defaultdict
import numpy as np
import pandas as pd
class BM25F:
def __init__(self, docs, v):
if len(docs) == 0:
print("Error. Empty document list.")
return
self.docs = docs # array of field term vectors
self.v = v # stream weight
self.N = 10000 # len(self.docs)
arr_docs = np.array(self.docs)
self.avsl = []
for stream_idx in range(arr_docs.shape[1]):
self.avsl.append(reduce(lambda sl1, sl2: sl1 + sl2, map(lambda s: len(s), arr_docs[:, stream_idx])) / len(self.docs))
def rank(self, q, b=.5, k=2):
if type(b) is not list:
b = [b] * len(self.docs[0])
# initialize
B_d = [] # B constant for docs
tf_q = [[] for _ in range(len(q))] # term frequency vector of docs for query terms
n_q = [0] * len(q) # doc frequency vectors for query terms
for idx_d, d in enumerate(self.docs):
B_s = []
tf_queryterm = 0
tf_stream = []
# initialize tf
for idx_q in range(len(q)):
tf_q[idx_q].append(0)
for stream, stream_weight, avsl, b_s in zip(d, self.v, self.avsl, b):
# provision
stream = np.array(stream)
# document length
sl = len(stream)
# B
B = (1-b_s) / (b_s * (sl / avsl))
# term frequency per stream
for idx_q, queryterm in enumerate(q):
stream_query_included = np.core.defchararray.find(stream, queryterm)
tf_queryterm_stream = len(stream_query_included[stream_query_included != -1]) * stream_weight / B
tf_q[idx_q][-1] += tf_queryterm_stream # add tf of the stream
# update document frequency
for idx_q, queryterm in enumerate(q):
if tf_q[idx_q][-1] > 0:
n_q[idx_q] += 1
# tf normalization
tf_q = np.array(tf_q)
# inverse document frequency
n_q = np.array(n_q)
idf_q = np.log((self.N - n_q + .5) / (n_q + .5))
# weight
w_q = (tf_q / (k + tf_q)) * idf_q.reshape((len(q), 1))
w = w_q.sum(axis=0)
docidx_ranked = w.argsort(axis=0)
# result as data frame
df_result = pd.DataFrame(columns=['docid', 'w', 'doc'], data={
'docid': list(range(1, len(self.docs)+1)),
'w': w,
'doc': self.docs
})
return df_result.sort_values(by='w')[::-1].reset_index(drop=True)
이제 몇몇 질의에 대한 랭킹을 해봅니다.
bm25 = BM25(docs_bm25)
bm25f_simple = BM25FSimple(docs_bm25f, [3, 1])
bm25f = BM25F(docs_bm25f, [3, 1])
q_list = [
['네이버'],
['네이버', '웹툰'],
['네이버', '후원'],
['네이버', '웹툰', '후원'],
['대통령'],
['총리'],
['대통령', '총리'],
['네이버', '문재인', '대통령']
]
df_result_list = []
for q in q_list:
df_result_list.append([bm25.rank(q), bm25f_simple.rank(q), bm25f.rank(q)])
이제 Term Frequency (TF)를 계산해 봅니다.
df_result_combined_list = []
for df_result in df_result_list:
df_result_combined_list.append(
pd.DataFrame(columns=['docid', 'w_bm25', 'w_bm25f_simple', 'w_bm25f'], data={
'docid': df_result[0].sort_values(by='docid').set_index('docid').index.values,
'w_bm25': df_result[0].sort_values(by='docid').set_index('docid')['w'],
'w_bm25f_simple': df_result[1].sort_values(by='docid').set_index('docid')['w'],
'w_bm25f': df_result[2].sort_values(by='docid').set_index('docid')['w']
})
)
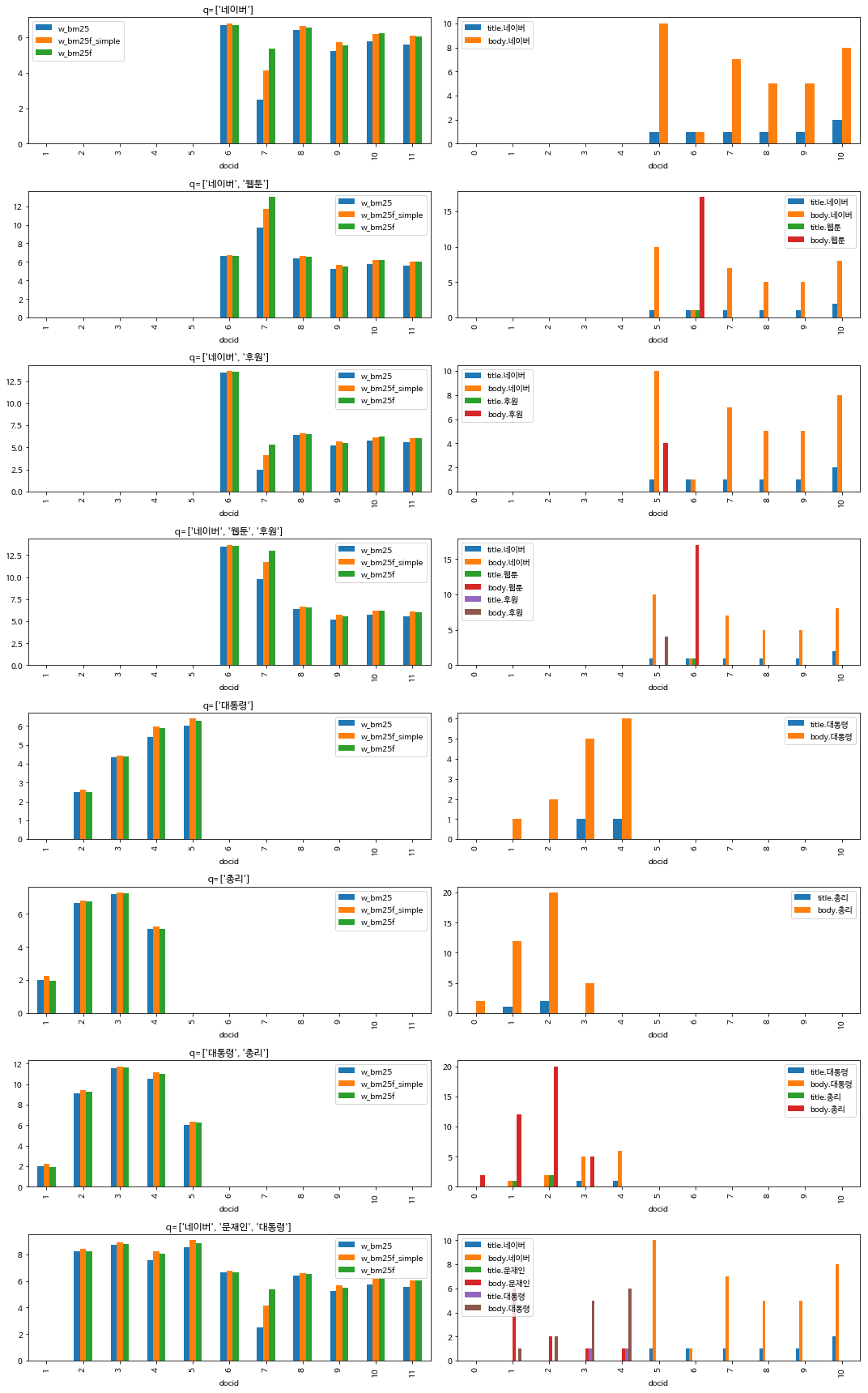
이제 계산한 BM25, BM25FSimple, BM25F 값과 TF를 가시화 합니다.
dflist_query_tf = []
for q in q_list:
df_query_tf = pd.DataFrame()
df_query_tf['docid'] = list(range(len(docs_bm25f)))
df_query_tf = df_query_tf.set_index('docid')
for queryterm in q:
title_tf = []
body_tf = []
for title, body in docs_bm25f:
title = np.array(title)
body = np.array(body)
title_query_included = np.core.defchararray.find(title, queryterm)
body_query_included = np.core.defchararray.find(body, queryterm)
title_tf.append(len(title_query_included[title_query_included != -1]))
body_tf.append(len(body_query_included[body_query_included != -1]))
df_query_tf["title."+queryterm] = title_tf
df_query_tf["body."+queryterm] = body_tf
dflist_query_tf.append(df_query_tf)
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
font_location = "/Library/Fonts/NanumBarunGothic.otf"
font_name = fm.FontProperties(fname=font_location).get_name()
matplotlib.rc('font', family=font_name)
%matplotlib inline
fig, axes = plt.subplots(nrows=len(q_list), ncols=2, figsize=(15, len(q_list)*3))
def plot(ax, df, title):
ax = df.sort_values(by='docid').set_index('docid').plot.bar(ax=ax, title=title)
for ax, df, q in zip(axes[:, 0], df_result_combined_list, q_list):
plot(ax, df, 'q=%s' % (q,))
for ax, df in zip(axes[:, 1], dflist_query_tf):
df.plot.bar(ax=ax)
fig.tight_layout()
가시화 결과입니다.